Danger Dungeon CS 175: Project in AI (in Minecraft)
1. Summary of the Project
Our project will involve training an agent to navigate a environment filled with dangerous traps and obstacles to overcome. It will be the agent’s goal to navigate the environment safely which will involve jumping over the traps as necessary to escape. Using Malmo along with some Reinforcement Learning algorithms the agent will take in a state which includes the agent’s current posititon in (x, y, z) format and the agent’s yaw (the direction the agent is facing). The agent’s reward for any one mission will be dependant on how close the agent was to the goal location by the end of mission’s running time. The action space will be continuous and include the following actions: moving forward, turning, and jumping. This action pool may have more or fewer actions in the future as we learn what creative features we can implement in the agent’s course.
** Project Clip
2. Approach
We have the agent traverses an obstacle course. The goal is for the agent to safely cross the lave river and reach the emerald on the other side of the course.
We design 2 separate experiment:
In the first experiment, the agent would be place in a big environment and could perform 3 actions: moving, jumping and turning.
In the second experiment, the agent would be place in a smaller environment and could only perform 2 actions: moving and jumping.
3. Evaluation
The agent will received a reward on the scale of 0 to 50, which is based on its end location when th timer runs out.
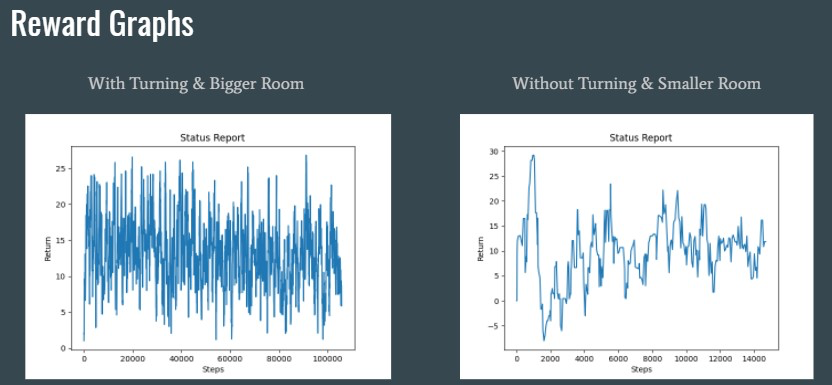
First Experiment - Bigger Room with Turning:
The agent had the ability to turn and was placed in a broad environment. The agent managed to travel around 100,000 steps but could only receive half of the reward and never managed to get over the lava line. We believe this is because the environment was too big and that lead to too many options.
Second Experiment - Bigger Room with Turning:
We took away the turning ability and placed the agent in a smaller environment. The agent managed to get more reward this time.
4. Remaining Goals and Challenges
Moving forward with this project we want to take some of the complexity out of the action space (continuous for our status report) and invest it into our map structure. We believe our agent’s learning was hindered by the continuous action space’s complexity, so for the final project we are going to switch back to discrete actions. In order to make our final experiments fun and interesting, we are going to create maps that dynamically change based on the actions our agent makes. Pressure plates, redstone, and pistons all allow for moving parts within the map. This will allow us to block off existing paths and create new ones that the agent will have to take into account during the learning process.
We also had trouble with our reward system. Our status report model only awarded reward at the end of the mission’s duration instead of incrementally throughout the mission’s lifetime. We believe this also contributed to our agent’s learning difficulty. For our final project, we are going to include reward checkpoints in the map to give the agent a better idea of what is a positive action or a negative action.
5. Resources Used
We used Homework 2’s code template as a skeleton for our reinforcement learning algorithm and modified the action and observation spaces to create our new enviroment and experiments. Our maps were created from scratch in the minecraft cilent and we imported it into our project using the appropriate XML tools.